
2018年3月6日,Google Brain 团队在distill上发表了7人共同完成的文章 《The Building Blocks of Interpretability》。两日后,Limber便迅速在Udacity上写了一篇文章来介绍Google Brain的这个最新成果:《再说深度学习是黑匣子,就把这篇文章互Ta脸上》。能拆黑匣子当然很让人兴奋了,遂找来原文读一读,不知道读完之后会不会产生把它糊到自己脸上的冲动。
一个解释神经网络的用户接口
目前,神经网络在很多方面的推断能力已经超过了人类。但是,我们不仅希望神经网络能推断以帮助我们决策,还希望它对做出的决策进行解释,即神经网络需要具备一定的可解释性(Interpretability)。Google Brain的这篇论文提供了一个用户接口,使神经网络能向“人”解释它看到了什么,以及它做出最终决定的依据。该接口整合了特征可视化、归因、以及降维等增强解释性的方法。
首先,这篇论文在可视化输入层和输出层的基础上,试图通过可视化(feature visualization)回答神经网络在隐藏层中看到了什么。这一步非常重要,因为每个隐藏层都能利用激活器对输入数据产生一个新的表征。从计算的角度,一个激活器(即单个神经元)表示为一个抽象的向量,因此很难从中得出相应的意义。而利用特征可视化可以把向量和一个更容易理解得”语义词典”进行一一对应。语义词典使我们能把神经网络学到的抽象向量和常规的实际概念联系起来。需要注意的是,尽管我们非常希望用明确的词语来概括每个语义词典,但这个操作是有损的。因为神经网络可能已经学到了人类无法察觉的细微差别,甚至它学到的概念是人类认知里没有的。更进一步,在每一个隐藏层,我们可以对同一空间位置的所有激活器对应的语义词典进行叠加,得到该位置叠加后的语义词典;根据激活程度的大小,我们可以比较各个空间位置探测到的特征强弱程度。
另一个问题是,我知道了神经网络所看到的,我也想知道它如何做出最终决定(例如判断一张图片中是猫还是狗)。各类问题概括为归因(attribution),是文中所提出的用户接口的第二个组件。归因最常用是显著图法,即把输入图像转化为简单的热点图,用颜色的深浅来表示每个像素点对最终判断的影响程度。显然,基于显著图的归因有至少两个问题:一、没有证据表明每个像素点应该是归因的最小单元;二、每次仅能为一个类别归因。为了解决这些问题,作者们在文章中对隐藏层进行归因,在更高层次地量化一个概念(即上一步中每一个隐藏层的所有通道叠加后的语义词典)对最终判断的重要性。对应通道叠加得到空间归因,我们还可以空间叠加得到通道归因,即各个通道对最终判断的影响程度。需要注意的是,虽然文中的神经元之间的关系用线性近似,文章提出的接口可以嵌入任何其他归因方法。
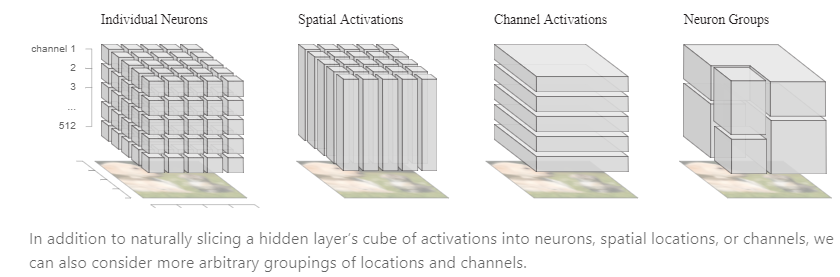
最后一步,神经网络的解释必须被“人”所理解,即最终展示的数据量必须是人类尺度,而不是一大堆纷杂的信息。在前面两步中,每一个隐藏层可以用三种方式进行划分:空间激活器集,通道激活器集,或者单个神经元。显然,任何以上任何一种划分都很难反映这个该隐藏层的整体状况。另一个问题是,这种划分方式最终信息太多了,试想,如果对每层几万的神经元进行特征可视化,我们几乎不能得到有用的结论,即便通过空间激活器集进行划分,几百个激活器集也很难描述。为了解决这个问题,文中采用矩阵因式分解的成组技术,如下图所示,最终大量的神经元被划分为很小数量的组(grouping)来更简洁地描述该隐藏层所见所想。隐藏层的矩阵因式分解过程本质上是一个权衡人类尺度和减少损失信息的过程,往往建模成多目标的最优化问题。
神经网络还是不是黑箱?
黑箱通常定义为,非基于物理定律的数学模型。黑箱包含的函数往往有很强的灵活性和泛化能力,但只是根据输入给出输出而不能解释模型参数对最终预测所起的作用。
我们不希望我们的模型是一个黑箱。因为拆开黑箱,往往意味着: (i) 在知道模型性能决定因素的基础上,预测模型实际生产中的表现;(ii) 探测到模型中可能存在的偏见(一定程度上与数据有关);(iii) 为建立更有效的模型提供洞察力。
在得出神经网络是不是黑箱的定论之前,我们不妨问自己以下几个问题:
- 各层参数的含义是什么?
- 影响神经网络决策的最主要因素是什么?
- 如何确定神经网络的结构?
可以看到,这三个问题是层层递进的。目前的研究,包括《The Building Blocks of Interpretability》,对前两个问题进行了很好的回答。反卷积特征图可视化等工作也在不断的进行过程中。而第三个问题涉及到的不仅仅是参数或者特征,它是一个模型选择的问题。对于确定性的模型,例如决策树或者线性回归,模型选择问题不存在,而对于结构变幻莫测的神经网络,这个问题则需要答案。
模型选择的难度显而易见,从传统的统计学习来看(我目前所做的贝叶斯推断也属于此类),神经网络属于一类不可识别的模型:给定数据集和网络拓扑结构,不同的模型参数可以得到相同的结果。
综上,从数学定义上,神经网络将长期是个黑箱,直至大脑研究的生物科技取得突破;从可解释性角度,神经网络已经是个可以解释的黑箱,但模型选择仍然未得到解释。
我们可能不喜欢黑箱,但不可否认黑箱的强大能力。神经网络对于各个方向的空间扩展以及不同空间域之间的相互作用能力,显示了其巨大的应用潜力。
关于distill
这篇文章发表在distill,这个去年推出的论文网站背后是Google Brain中诸如Ian Goodfellow的大神。distill上的论文在网上发表,采用便于网上阅读的格式,采用交互图片,同时也有doi和传统文章发表的同行评审过程。目前,arXiv上的文章不断抢占idea高地,对idea的理论推导和具体implementation有意无意的忽视;学术期刊上的文章,又饱受各大出版商(elsivier, springer)的压榨。正如某云说的,“银行不改变,我们就来改变银行”,distill仿佛在说:“出版商不改变,我们就来改变出版商”。